0.Abstract
-생략
1.Introduction
- Transformer를 computer vision에 대한 적용은, 특정한 tasks(e.x., image classification, joint vision-language modeling에서 유망한 결과를 낳았다.
- 본 논문에서는, Transformer를 NLP와 CNN이 vision에서 하는 능력과 마찬가지로 computer vision에서 general-perpomance backbone이 되기위해 적용가능성의 확장을 탐색한다.
- 본 논문에서, language domain에서 visual domain으로 이전하는 데 있어 상당한 차이가 두 양식(modalities) 간의 차이로 설명될 수 있다는 것을 발견하 였다. 이 차이 중 하나는 scale에 관련이 있다.
- language Transformers의 처리의 기본 요소인 word tokens와 다르게, visual elements은 상당히 scale이 다를 수 있다. 이는 object detection과 같은 task에서 주의(attention)를 받는 문제이다.
- 기존에 존재하는 Transformer가 기반인 model들은 tokens은 고정된 크기이고, 이러한 특성은 visual applications에 적합하지 않다.
-또 다른 차이점은 텍스트 구절의 단어에 비해 이미지 픽셀 해상도가 훨씬 높다는 것이다.
- vision tasks에는 semantic segmentation와 같이 pixel level에서 dense prediction이 필요한 경우가 존재하고, 이는 고해상도 영상에서 Transformer의 self-attention의 computational complexity가 영상 크기에 제곱이기 때문에 다루기 어려울 것이다.
- 이러한 문제를 해결하기 위해, 본 논문에서는 Swin Transformer라고 불리는, 계층적(hierachical) feature maps를 구성하고, image size의 선형 computational complexity를 가지고 있는 general-purpose Transformer backbone을 제안한다.

- Figure 1(a)에서 illustrate되었듯이, Swin Transformer은 small-sized patches로 시작하면서 계층적 representations을 구성하고, 더 깊은 Transformer layer에서 인접 patches를 점차 병합한다.
- 이러한 계층적 feature map을 통해 Swin Transformer model은 feature pyramid network(FPN)이나 U-Net 같은 dense prediction을 위한 고급 기술을 편리하게 활용할 수 있다.
- linear computational complexity의 경우 이미지를 분할하는 겹치지 않는 창(빨간색으로 표시)내에서 local로 self-attention을 계산함으로써 얻을 수있다.
- 각각의 window의 patch 수는 고정되어 있고, 그렇기 때문에 complexity는 image size에 선형이 되게 된다. 이러한 이점 때문에 Swin Transformer는 단일 해상도 feature map을 생성하고 2차 복잡성을 갖는 이전의 Transformer 기반 architecture와 달리 다양한 Vision Task의 general backbone으로 적합하게 된다.

- Swin Transformer의 key design 요소는 Figure 2와 같이 연속된 self-attention layer간의 window partition 이동이다. shifted된 window는 이전 층의 window에 bridge를 달아 modeling capacity를 크게 향상시키는 연결을 제공한다.(표 4 참조).
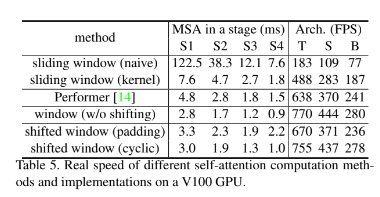
-이러한 전략은 실제 지연 속도(latency)에 대해서도 효율적이다. window 내의 모든 query patch는 동일한 key set1를 공유하기 때문에 hardware memory access가 용이해진다.
- 이와 반대로, 이 전의 self-attention을 base로 한 sliding window 접근법의 경우 다른 query pixel에 대한 다른 key sets로 인해 일반 하드웨어에서 낮은 지연 시간을 겪는다.
- 본 논문의 실험에서는 shifted-window가 sliding window method보다 훨씬 적은 지연 시간을 갖지만, modeling power는 비슷하다는 것을 보인다. 또한 이런 shifted window approach는 모든 MLP architectures에 유익하다는 것이 입증되었다.
- 제안된 Swin Transformer은 이미지 classification, object detection 및 semantic segmentation에서 강력한 성능을 달성한다. ViT/DeiT및 ResNe(X)t모델을 크게 웃도는 퍼포먼스를 발휘한다. COCO test-dev set의 58.7 box AP 및 51.1 mask APsms +2.7 boxAP(copy-paste without external data)및 +2.6 mask AP(DetoRS)만큼 이전 최신 결과를 능가한다. ADE20K의미 분할에서, 그것은 val set에서 53.5 mLOU를 얻으며, 이는 이전 state-of-art보다 +3.2 mIOU의 개선이다. 또한 ImageNet-1K 이미지 분류에서 87.3%의 최고 정확도를 달성한다.
2.Related Work
생략
3.Method
3.1 Overall Architecture

* Swin Transformer block
- Swin Transformer은 Transformer block안에 있는 standard multi-head self attention (MSA) module을 shifted window(described in Senction 3.2)를 기반으로한 module로부터온 Transformer block으로 대체하면서 만들어졌다.
- Figure 3(b)에서 illustrate된 것처럼, Swin Transformer block은 shifted window based MSA module로 이루어져 있고 그 이후 2개의 MLP와 그 사이의 GELU non-linearity가 있다.
- LayerNorm(LN) layer가 각각의 MSA module전과 MLP전에 적용되고, 그리고 residual connection module이 그 이후에 적용된다.
3.2 Shifted Window based Self-Attention
- standard Transformer architecutre과 image classification을 위한 이것의 적용은 둘 다 global self-attention을 수행하고, 그렇기 때문에 token과 모든 다른 tokens 사이의 관계가 계산된다.
-이러한 global computation은 token의 수의 따른 제곱의 복잡성을 야기하고, dense prediction 또는 high-resolution image를 표현하기 위해 방대한 token set를 필요로 하는 많은 vision problem에 적합하지 않다.
* self-attention in non-overlapped windows
- 효율적인 modeling을 위해, 본 논문에서는 local windows내에서 계산하는 self-attention을 제안한다. window는 겹치지 않도록 image를 균등하게 분 할할 수 있도록 배치되어 있다.
- 각각의 window가 M*M patches를 가지고 있다고 가정해보면, global MSA module과 h*w patches의 이미지에 기반한 window의 계산 복잡도는 다음과 같다.

- (1)의 경우는 patch number h*w의 제곱에 비례하는데, (2)의 경우는 M이 고정되어있을 경우(보통은 7로 둠) h*w의 선형으로 비례하는 것을 알 수가 있다.
* shifted window partitioning in successive blocks
- window 기반 self-attention 모듈은 window 간 연결이 부족하여 modeling 성능이 제한된다. 겹치지 않는 창의 효율적인 계산을 유지하면서 cross-window connection을 도입하기 위해 연속된 Swin Transformer block의 두 파티션 구성을 번갈아 사용하는 shift window partition 방식을 제안한다.
-Figure 2에서 보여주듯이, 첫 module은 왼쪽 상단 pixel에서 시작하는 regular window partitioning을 사용하며, 8*8 feature map은 4*4(M=4)크기의 2*2 창으로 균등하게 분할된다. 그런 다음, 다음 모듈은 window를 정기적으로 분할된 window에서 ([M/2], [M/2]) pixel 단위로 표시함으로써 이전 layer의 window 구성보다 이동된 window 구성을 적용한다. shifte window partitioning 접근 방식을 사용하면 연속된 Swin Transformer block은 다음과 같이 계산된다.


- shift window partitioning 접근 방식은 이전 layrer에서 겹치지 않는 인접 윈도우 간의 접속을 도입하여 표4와 같이 image classification, object detect 및 semantic segmentation에 효과적이라는 것을 알 수 있다.
* Efficient batch computation for shifted configuration
- shifted window partitioning의 issue는 shifted 배열에서, [h/M]*[h/M]에서 [h/M + 1]*[w/M+1]까지 더 많은 windows 만들어 낸다는 점이였고, 몇몇의 window는 M*M보다 작게되는 문제가 있었다.
- 이것에 대한 naive solution은 작은 창을 M*M 크기로 padding하고 attention을 계산할 때 padding된 값을 masking하는 것이였다. 그러나 이는, 예를들어, 2*2의 경우 naive한 solution을 이용하는경우 증가된 computation은 상당하였다.(2*2에서 3*3의 변화는 2.25만큼 더 크므로!)
- 본 논문에서는 figure 4와 같이 왼쪽 상단 방향으로 cyclic shift함으로써 보다 efficient한 batch computation approach를 제안한다. 이러한 shift 후에, batched window는 feature map에 인접하지 않은 여러 sub window로 구성될 수 있으므로 masking mechanism을 사용하여 self-attention computation을 각 sub-window 내에서 제한한다.
- cyclic-shift에서는 일괄 처리된 window 수가 일반 window 분할의 수와 같기때문에 효율적이기도 하다. 이 접근법의 낮은 latency는 Table5에 나와 있다.
* Relative position bias
- self-attention을 계산하는 과정해서, 본논문에서는 기존 기법을 따라 계산 유사성에 있어서 각 head에 대한 relative position bias B를 포함시킨다.

- 표 4와 같이 이 bias 항이 없거나 absolute position embedding을 사용하는 상대 제픔에 비해 상당한 개선을 관찰한다. 또한 absolute position embedding을 입력에 추가하면 성능이 약간 떨어지기 때문에 본 논문의 구현에서는 채택되지 않았다.
- pre-training에서 학습된 relative position bias는 bicubic interpolation을 통해 다른 window 크기를 가진 fine-tuning을 위한 모델을 초기화(initialize)하는데 사용될 수도 있다.
3.3 Architecture Variants

4. Experiments

-- ..ing



